Industry news
保姆级笔记-详细剖析SMO算法中的知识点
序列最小优化算法(Sequential minimal optimization)-SMO算法
SVM算法中原问题的对偶问题是一个凸二次规划问题,同时解这个凸二次规划问题的计算复杂度跟样本的数量有关。当样本数量很大的时候,很多解法就会变的非常低效,以至于无法使用。如何高效的解决这个问题,就是我们要研究的问题。而SMO算法刚好是解决这个问题的好办法。
在开始讲SMO算法之前,我们先介绍一下坐标下降法。大家以前在学梯度下降法的时候,我们总是朝着梯度最大的方向去搜索最优解。而梯度最大的方向,是各个坐标轴方向梯度的向量相加后的那个方向。
而在坐标下降法中,我们把其他几个方向固定,只沿着某一个坐标轴的梯度方向去搜索。因为在一次坐标下降中,我们只有一个变量,所以计算的复杂度大大降低。这样一个复杂的问题,就被分成好多的小问题来解决。
在下图的例子中,我们可以看到,先沿着y轴的方向前进,再固定y沿着x轴的方向前进,最后也能达到最优解的位置。【下面这幅等值线图,我相信大家应该都能看懂,不懂可以留言。】
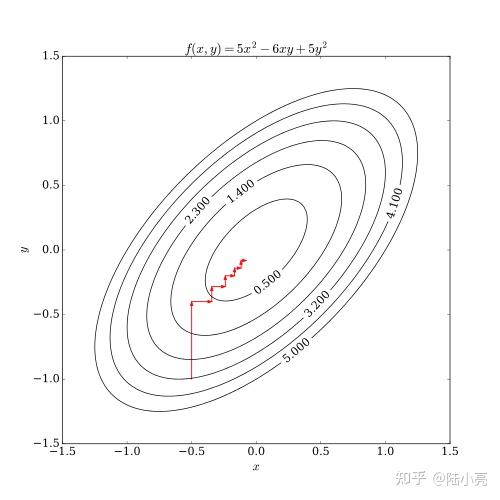
SMO算法跟坐标下降法类似,选择两个变量,固定其他的变量,针对这两个变量构建一个二次规划问题。这个子二次规划问题的解,会更接近原始二次规划问题的解。原因很简单,通过这次子二次规划的求解,会使得原始二次规划问题的目标函数值变的更小。等下给大家展示原始问题的公式,会发现是一个求最小值的问题。如果一组解能够使得问题的值变得更小,那么这组解是不是更接近我们的答案呢?
在李航老师的书中p143页, 是用
来表示的,我们后面也会用K来表示,但为了推导更为清楚,我们先这么表示。上述问题已经是软间隔最大化推导过来的,具有一般性。
整个推导过程是记录了大海老师的课程笔记+我自己的理解,大家也可以通过下面的链接直接去看视频,但要完整的看下来,需要耐心。
机器学习 svm_smo算法_哔哩哔哩_bilibili
机器学习 svm_smo算法_哔哩哔哩_bilibili为了不失一般性,我们选择 和
作为我们的变量,其他变量都固定。
这里看着我们是有两个变量 和
,但其实他们之间是有约束的,约束是
。所以其实只有一个变量。所以我们这个子问题就是一个一元二次方程的问题,我们可以通过带入消元,把
消掉来求解函数的最小值。
我们令
进一步化简,其中 和
是常数,我们在后面的式子中把他们省略,因为他们不影响我们求导。
是固定的,所以
我们把 带入
, 得:
我们要求最小值,对于一元二次方程,我们就是求导。
再化简
在SVM对偶算法中(李航老师的书p120页),我们有一个结论,
又因为 ,所以
所以
所以
,又因为有
,
所以
同理
我们把公式1和公式2,带入到公式1中,得
那这里有个常量 ,
等于多少呢?我们说SMO算法其实是个迭代的算法,我们会给
附上初始值为
,从前面的推导可知
所以 ,带入公式4, 得
公式(6)
如下图做合并同类项, 得公式6
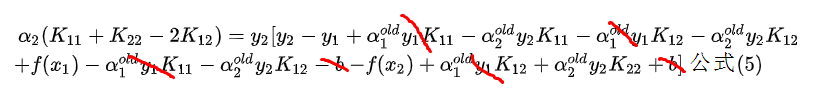
经过整理,公式6为:
在上述推导中求得的 是未经过剪辑的,我们记作
。剪辑过的记作
什么叫做未剪辑呢?很多同学看书的时候是有疑惑的,下面我们来解释一下。
首先 是我们通过求导数为0,而得到的极值点。
通过条件 ,我们可知
的取值是有约束的,换句话说
的取值是有范围的。
的取值能落在
的取值范围内吗?
我们假设L是 取值的下界,H是
取值的上界,即
举例:
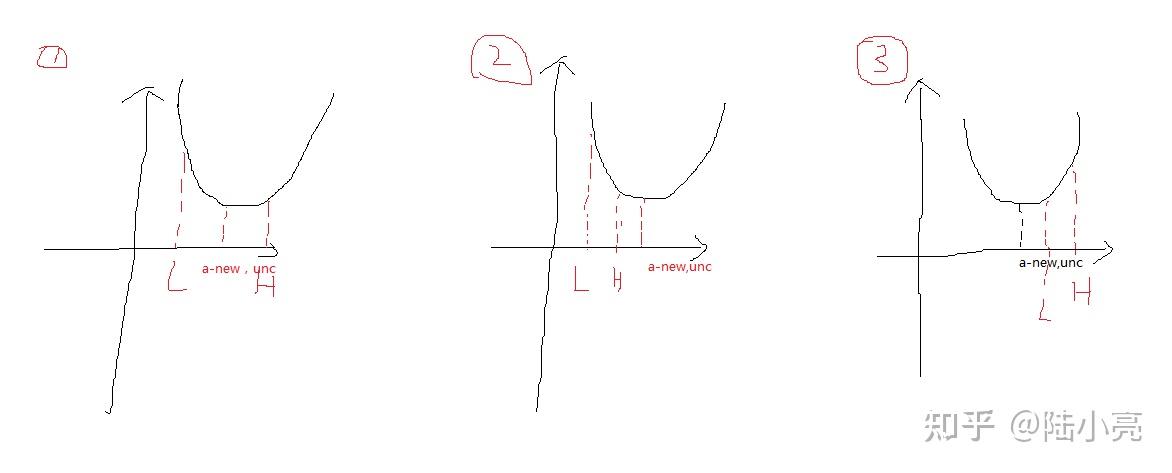
从上图中我们可以看出,当函数取最小值的点是最优解:
第一种情况: ,当
第二种情况: ,当
第三种情况: , 当
我们分两种情况进行讨论:
前提:
情况1: (根据y1和y2取值的不同,k可能等于
或者
)
因为 ,
所以
又因为
所以要取交集,则 ,
情况2:
因为 ,
所以
又因为
所以要取交集,则 ,
SMO方法中的核心就是选取两个 ,但我们有N个
,如何从中选取两个呢?
核心思想就是至少选择一个变量是违反KKT条件的。那怎么样算违反了KKT条件呢?反过来理解,就是怎么样算满足KKT条件呢?
软间隔最大化的原问题:
,
为松弛变量,C为惩罚函数
我们改写成最优化问题的标准形式:
,
为松弛变量,C为惩罚函数
原始最优化问题的拉格朗日函数是:
根据KKT条件可得:
(1)
(2)
(3)
(4)
(5)
(6)
(7)
根据 的取值,分情况讨论:
首先我们令
当 ,根据条件(4),则
,有
当 ,根据条件(3)可知
,再根据条件(7)可知
,再根据条件(6)可得
当 ,根据条件(3)得
,再根据条件(7)可知
,再根据条件(6)可得
,所以
所以满足KKT条件,就可以用下列式子进行判断(简化以后的式子方便编程啊):
SMO称选择第一个变量的过程为外层循环。外层循环在训练样本中选取违反KKT条件最严重的样本点,并将其对应的变量作为第一个变量。
首先遍历 的样本点,即在间隔边界上的支持向量点,检验他们是否满足KKT条件。如果都满足,则遍历整个训练集,检验它们是否满足KKT条件。
SMO将第二个变量的选择过程成为内循环。假设外层循环已经找到了第一个变量 ,现在要在内层循环中找第二个变量
。而第二个变量选择的标准就是希望
能有足够大的变化。而我们根据前面的推导可得:
所以 依赖于
。
那我们选择一种最简单的方法,我们找到一个 ,使得
最大。
如果遇到特殊的情况,内层循环通过上述方法选择的 不能使目标函数有足够的下降,那就采用启发式规则继续选择
。首先遍历在间隔边界上的支持向量点,依次作为
试用,直到目标函数有足够的下降。若这样还找不到,那就遍历整个训练集。若仍然还是找不到,则放弃第一个
,重新找一个新的
。
完成两个变量的优化后,都需要重新计算b
当 ,可知
,得
,
于是 (1)
根据E1的定义 (2)
所以 (3),带入(1)中
得
同理,如果 ,则
如果 ,则
如果
还要更新 ,
,其中S为所有支持向量点
的集合。
优化算法——坐标下降法(Coordinate Descent) - 知乎
ARGO创新实验室:优化算法——坐标下降法(Coordinate Descent)快速理解SMO算法_哔哩哔哩_bilibili
快速理解SMO算法_哔哩哔哩_bilibili机器学习 svm_smo算法_哔哩哔哩_bilibili
机器学习 svm_smo算法_哔哩哔哩_bilibiliSMO算法的推导与python实现 - 知乎
葛溪驿:SMO算法的推导与python实现Categories
耀世新闻
Contact Us
Contact: 耀世-耀世平台-耀世全球商务站
Phone: 13800000000
Tel: 400-123-4567
E-mail: admin@youweb.com
Add: Here is your company address

